It’s time for some jargon-busting.
A big part of my role is to onboard and support junior data analysts. A lot of them have just started using SQL, have come from the world of Excel analysis and have self-taught the SQL basics.
Here are some of those terms and concepts that pop up during training if you need a refresher or have a junior analyst in your life that needs something to refer back to.
Alias
Begin transaction
CTEs v subqueries
Design
ETL
Function
Group by
Heaped storage
Integrity
Join
Key
Lock
Massive parallel processing
Normalisation
OLTP v OLAP
Privileges
Query plan
Disaster recovery
System tables
Truncate v Drop
Union
View
Window function
XML
Year
Zero
Alias
When joining tables, we need to state which column from which table we want to match up, and which columns we want to return in the results. If there are columns with the same name we need to be specific about which column we want to return.
select
orders.item,
inventory.item,
inventory.unitprice
from
orders
inner join
inventory
on orders.order_item = inventory.inventory_item
To make it quicker to type we can alias the two tables with something shorter.
select
o.item,
i.item,
i.unitprice
from
orders o
inner join
inventory i
on o.order_item = i.inventory_item
Instead of having to type out the whole table name each time we want a new column added, we can alias them with the letter ‘o’ for orders and ‘i’ for inventory.
Begin transaction
SQL Transactions are used to trap errors when making changes to tables. During an UPDATE or DELETE statement, the change is auto-committed.
By wrapping the statement in a transaction we have the opportunity to ‘roll back’ or ‘commit’ when we are sure that it should be executed, or if a condition has been met.
The following transaction will run in a block and commit if successful.
begin transaction
update orders
set status = 'sent'
where order_id = '12345'
update orders
set status = 'sent'
where order_id = '54321'
commit transaction
CTEs v subqueries
CTEs (Common Table Expressions) are a temporary, named result set we can come back to in the scope of a single SELECT, INSERT, UPDATE, DELETE or MERGE statement.
I use them when dealing with large tables to. For example: get all the columns I need from the ’emailsent’ table, then get all the columns I need from the ’emailunsubscribe’ table. Then in a final step join them together.
Design
Datamarts tables are organised in one of two forms. A ‘star’ schema and a ‘snowflake’ schema made of two types of tables.
- Facts – that count how many times something has happened.
- Dimensions – that describe an attribute.
In the star model, we can have a sales table as our fact in the centre. Dimension tables for the store, product and location surround the fact like a star.
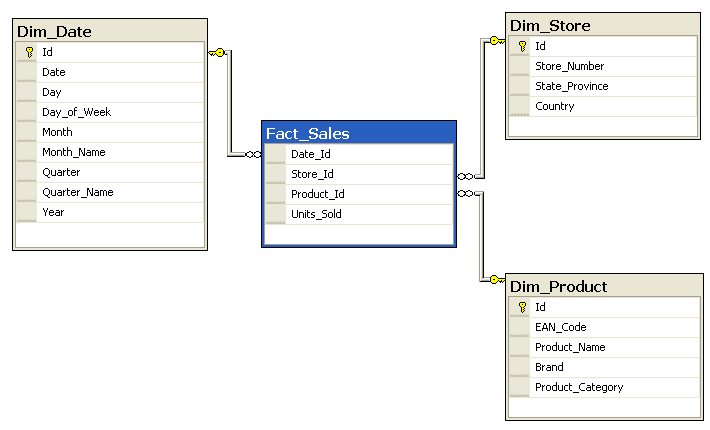
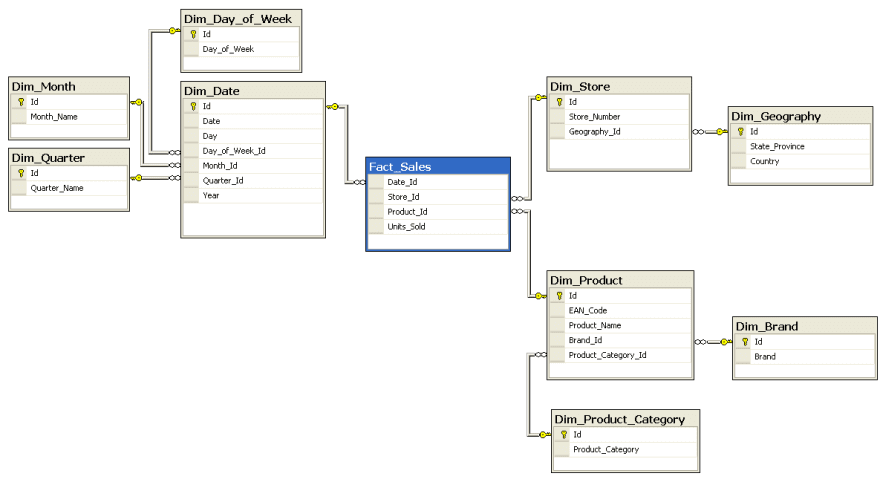
The snowflake is similar but takes the dimensions one step further. Instead of just a location table, we may have a city, country and even a postcode table. All the dimensions become the points on the snowflake.
ETL
ETL and ELT are the steps involved in moving data from a source system to a destination system.
- Extract – in the extract step the raw data is moved from source to a temporary or staging area.
- Transform – the transform step converts the data so matches the destination table.
- Load – the load step moves the data into its final destination so it can be used in analysis or reporting.
ETL is the order that these steps are traditionally performed in. ETL is great for putting data into the right format, stripping out unnecessary columns, and masking fields relating to GDPR compliance.
However, ELT has become a more popular approach when used in conjunction with data lake architecture. The data arrives quickly as it does not have to be altered in any way. The data scientist can then use just the data they need, quickly get results, and not have to deal with delays if a transformation step fails.
Considerations need to be made around how reliable the data is in its raw form. Each data scientist or end-user will need to apply the same logic and business rules when conducting analysis to keep results consistent.
Function
In PostgreSQL, we can execute blocks of code, called Functions, on a schedule. They can be written like the statements we run ad hoc on the database or can be parsed variables to make them dynamic.
Group by
Aggregate functions allow us to perform calculations on fields. The most common ones are SUM, COUNT, MIN, MAX, AVERAGE.
For example, to see the total amount due for each item in the orders table we can use the SUM of the amount_due column and GROUP BY
select
order_item,
sum(amount_due)
from orders
group by order_item;
Heaped storage
Heaped storage is a term for tables that live on the database with no clustered index. The data is stored in no particular order and new data simply gets added as it comes in.
Indexes are a way of telling the database to order the data or where to look to find the data you query often.
- Clustered indexes are like the contents page of a book. Applying this kind of index is telling the data how it should be ordered, like the pages in a book.
- Non-clustered indexes are like the index of a book, the pages haven’t been arranged that way physically, but you now have a lookup to get to what you need faster.
Integrity
This refers to data quality and rules ensuring data is traceable, searchable and recoverable.
- Entity integrity – each table must have a unique primary key
- Referential integrity – foreign keys on each table refers to a primary key on another or is NULL
- Domain integrity – each column has a specific data type and length.
Join
Because our database contains tables that are normalised you may not find all the data you need on one single table. To put the data back together in a way that makes the most sense for us we use JOINs. This adds columns from multiple tables into one dataset.
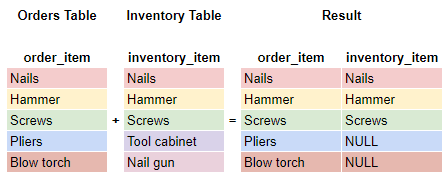
Use an INNER JOIN, shortened to ‘JOIN’, when you want to find the match between two tables. You need to have a column on both tables that you join ON, and that’s where the match happens. Any results where there is not a match are discarded.

Use a LEFT JOIN when you want to find a match between two tables, but also show a NULL where there is no match from the right table. A RIGHT JOIN does the same but in reverse.
Like the INNER JOIN, you need a column to join ON. Unlike the INNER JOIN, a NULL is used to show there is no match between the two tables.
Key
A primary key is a column that best identifies one unique row, and identifies each record as unique, like an ID
- It ensures that there are no duplicates
- It cannot be unknown (NULL)
- There can only be one primary key per table
A foreign key is a column that matches a primary key in another table and enforces integrity between the two.
To create a primary key in SQL Server add the reserved words ‘primary key’ after the data type of your chosen column.
create table students (
id int not null primary key,
firstname varchar(255) not null,
lastname varchar(255) not null,
);
Lock
When two users are trying to query or update the same table at the same time it may result in a lock. In the same way that two people with ATM cards for the same bank account are trying to withdraw the same $100 from the same bank account, one will be locked out while the first transaction is completed.
Rhymes does a great job of explaining how it works on the database:
“…database locks serve the purpose of protecting access to shared resources (tables, rows, data).
In a system where tens if not hundreds of connections operate on the same dataset, there has to be a system to avoid that two connections invalidate each other’s operation (or in other cases causing a deadlock) …
Locks are a way to do that. An operation comes to the database, declares they need a resource, finishes its own modification, then releases such resource so the next operation can do the same. If they didn’t lock their resource two operations might overwrite each other’s data causing disasters.
Massive parallel processing
In data warehouses like Redshift, data is partitioned across multiple compute nodes with each node having memory to process data locally.
Redshift distributes the rows of a table to the nodes so that the data can be processed in parallel. By selecting an appropriate distribution key for each table, the workload can be balanced.
Normalisation
Database normalisation increases data integrity and allows new data to be added without changing the underlying structure.
- Eliminate or minimise duplication – repeating a value across multiple tables means that tables take up more space than needed which increases storage costs. Storing customers address details on one table with keys linking to their orders will take up less space than repeating address details on each row of the order table.
- Simplify updates to data – by keeping a value in one table with a key to another we minimise the risk of errors when there are updates to be made. If there are two places where a customers email is stored and only one gets updated there will be confusion over which one is correct.
- Simplify queries – searching and sorting become easier if there is no duplication on tables.
OLTP v OLAP
OLTP and OLAP refer to different types of databases and tools that perform different functions.
- Online Transaction Processing (OLTP) – used for fast data processing and responds immediately to queries.
- Online Analytics Processing (OLAP) – used for storing historical data and data mining.
Privileges
If you intend on sharing a table with your colleagues who have access to your schema, you need to explicitly grant access to them. This keeps data locked down to just those who need to see it.
GRANT ALL ON <schemaname.tablename> TO <username>
-- if you would like them to SELECT, UPDATE and DELETE
GRANT SELECT ON <schemaname.tablename> TO <username>
-- if you would like them to be able to only SELECT
Query plan
When we run a query there are many things that the SQL engine considers – the joins, the indexes, whether it will scan through the whole table or be faced with table locking.
In SQL Server we can use the execution plan to visualise runtime information and any warnings.

In PostgreSQL we can check the query plan using the EXPLAIN command:
EXPLAIN -- show the execution plan of a statement
EXPLAIN ANALYZE -- causes the query to be executed as well explain
Recovery
Disaster recovery in the database world relates to the backups, logs and replication instances that are maintained while everything is working fine. These can then be switched on, switched over and analysed when something does go wrong, like a hardware failure, natural disaster or even human error.
- Failover – multiple clusters are set up so if one fails the other can take over.
- Mirroring – maintaining two copies of the same database at different locations. One in offline mode so we know where things are at when we need to use it.
- Replication – the secondary database is online and can be queried. This is not only good for Disaster Recovery but can be useful if you utilise one instance for reporting and one for live queries. If you are using AWS setting this up takes just a few clicks.
System tables
In SQL Server these are often referred to as system tables and views. They can be found in the master database, which holds data about the database. And in the system views within each database for specific information about each database.
In PostgreSQL, a similar collection of tables can be found in the information_schema and PostgreSQL catalog.
Examples of system views:
- sys.objects – shows each object, its type and created date
- sys.indexes – shows each index and type
- information_schema.columns – shows each column, it’s position and datatype
Examples of catalog objects:
- information_schema.tables – shows each object, its type and created date
- pg_index – shows each index and type
- information_schema.columns – shows each column, it’s position and datatype.
Truncate v Drop
Both of these commands will remove the data from a table but in different ways.
- TRUNCATE is a DDL command which removes the contents of the table while leaving the structure in place
truncate table marketing.emailcampaign
- DELETE is a DML command which removes rows given a WHERE clause
delete from
marketing.emailcampaign
where
month = 'January'
Union
While a JOIN combines rows of columns horizontally, a UNION combines the results vertically. Using a UNION combines the result of two queries into one column and removes duplicates. If your query has multiple columns, they need to be in the same order to complete the UNION.
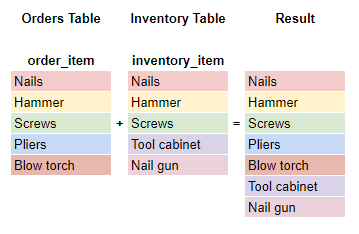
select *
from
orders
union
select *
from
inventory
The UNION ALL combines the results of two queries the same as a UNION but keeps the duplicates in the result.
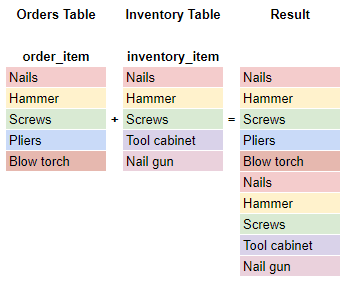
select *
from
orders
union all
select *
from
inventory
View
Views are not tables, they are queries that are executed on the fly and are used as a way to create a level of abstraction from the base table.
Joe sums it up perfectly in his post
A view is a stored query. When you create a database view, the database stores the SQL you gave it. Then, when you come along and query that view, the database takes the stored view query, adds in the extras from the query against the view, and executes it. That’s it!
Window function
A window function gets its name because, unlike an aggregate function, it keeps each row intact and adds a row number or running total.
Here is an example using the orders table that returns a rank using the order_value.
select
order_id,
order_name
order_date,
rank() over(order amount_due desc)
from
dbo.orders
XML
We can import files into tables using the import/export wizard. But they don’t have to just be csv or txt files. By using a few lines of code we can import XML as well.
Year
Depending on your flavour of SQL you will be able to calculate the difference between two dates and compare a date with the current date. There is added complexity when moving between databases so keep this in mind when on your next migration.
Zero
NULL means that the value is unknown, not zero and not blank. This makes it difficult to compare values if you are comparing NULLs with NULLs.
Because NULL is not a value it isn’t possible to use comparison operators. Instead, we need to use the IS, and IS NOT operators:
select *
from
inventory
where
unitprice is not null
By default, NULLs will appear as the largest value and making sorting at best annoying and at worse misleading. To get around this we can use COALESCE to treat NULLs as a 0.
select
itemname,
coalesce(unitprice, 0)
from
inventory
order by 2
There we have it, a quick introduction to the key terms, concepts and jargon for those new to the world of SQL and databases.
Photo by Polina Zimmerman from Pexels